
Check out the infographic below for some information about one of our studies! You can visit our Publications page or click here for the paper, the preprint, and the OSF repository.
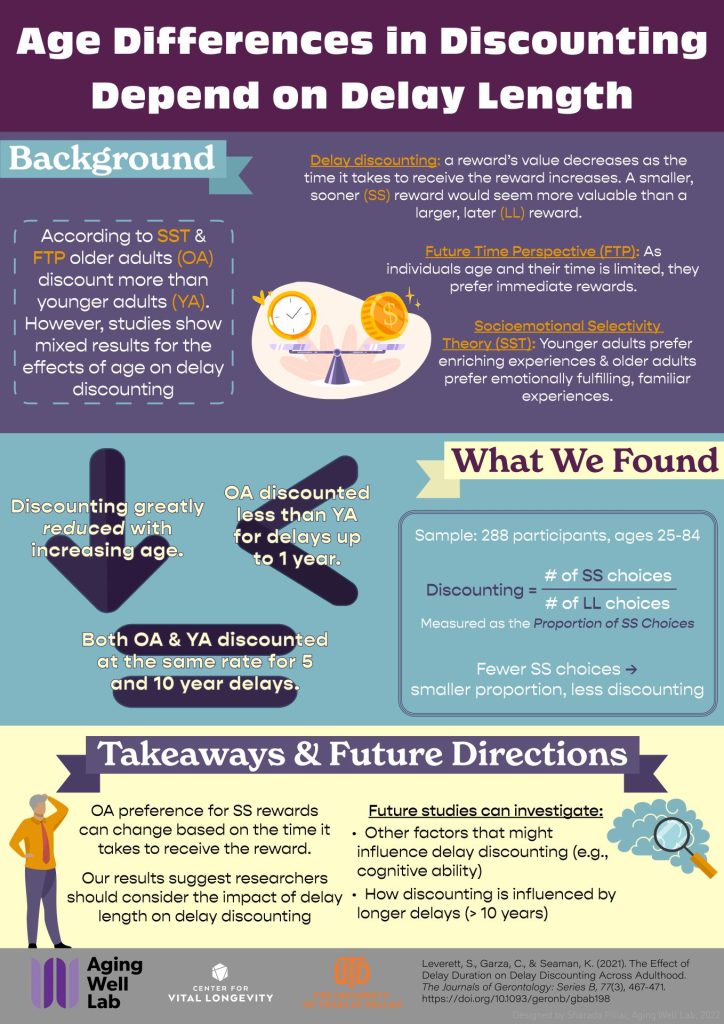
Check out the infographic below for some information about one of our studies! You can visit our Publications page or click here for the paper, the preprint, and the OSF repository.
Before anyone gets confused, yes, the Aging Well Lab still conducts psychology research, and no, we aren’t moving our lab space to Silicon Valley. As it turns out, coding is a very relevant skill for most research disciplines. Many neuroscientists and psychologists use coding software to create tasks or “games” to collect data, and statistical languages like R are used to analyze participants’ behavior.
Some labs use proprietary software like the Statistical Package for the Social Sciences (SPSS) or Jeffrey’s Amazing Statistics Program (JASP). They are menu-driven, like Excel, and don’t require prior coding experience. Users can analyze their data by pushing buttons presented by the software, but there isn’t any record of the changes made to the data by the program. Other labs, like ours, use scripts written in languages like R or Python to analyze their data. Scripts can track every change that has been made to data, which allows the researcher to easily re-run analyses, detect and fix errors, and share their methods with other researchers.
Have you ever had multiple versions of a paper for a class and had trouble keeping track of which version you were working on? Platforms like Box or Dropbox provide an efficient way to track changes made to a document. This is known as version control. However, these platforms are often restricted to applications like Word, PowerPoint, and Excel. Git provides the same functionality, but works specifically for code.
All bolded words in this article are defined here.
Git is a free version control software that uses an application already on your computer. This application, called the command line (a.k.a. terminal, console, CLI), is essentially a small black window that you can use to type commands for your computer. Typing “git” before a command tells the computer to use Git for the action you want to execute.
Each new line in the terminal will start with a prompt: either $ (Mac/Linux) or > (Windows). Command line tutorials usually include prompts in their examples, but keep in mind that you only have to type everything that follows the prompt, not the prompt itself. From this point forward, I’ll be formatting my commands with the prompt as well.
Check out this command line cheat sheet if you need some help!
The command line is like a horse with blinders; it can only focus on what’s right in front of it and needs step-by-step guidance to know what you want it to do. When working in the command line, you have to make sure that it’s able to see the file or folder you’re working on. Either the top of the command line window or the prompt indicates the folder it’s currently “seeing”. Always make sure the command line is seeing the correct folder, especially when using Git!
“Saving” in Git, known as committing, is different than saving something like a Word document. Saving your script using ctrl + S/cmd + S keeps the most up to date version of your file on your computer and discards previous versions. Committing your changes to Git requires using the command line, and you can commit multiple files in one go. Each time you commit a file (or files), Git takes a snapshot of the changes you’ve made from previous versions rather than saving the entire document again.

Git is incredibly useful, but it doesn’t automatically work with every folder or file on your computer. You first have to create a folder, or directory, to store any files related to your code. Consolidating these files in a directory also makes that folder a repository, or repo. In the command line, change directories to your repository and type “git init” to connect it to Git. Now you’ll be able to use Git to commit the changes you make for all the files in your repository.
It’s good practice to check on the status of your repo, especially before committing. Type
$ git statusin the command line, and it’ll tell you which files in your repo have been modified, deleted, and added since your last commit. Then, you have to prep, or stage, the files you want to commit.
I’m using R to work on some code, and have 4 files in my repo: fileA.R, fileB.R, fileC.R, and fileD.R. For fileA, fileB, and fileC, I added one line of code to calculate a sum. In fileD, I removed a couple of lines that kept returning an error message. Once finishing work for the day, I check the status of my repo, it tells me that all 4 of my files are not staged for commit. I could type $ git add fileA.R$ git add fileB.R$ git add fileC.R
as separate lines, but that can be tedious. Instead, I type$ git add *
which stages all unstaged files in your repo. Now I also have fileD staged, but I made different changes to fileD and don’t want to commit it with my other 3 files. To unstage fileD, I type$ git rm fileD.R.
Once again, I’ll type in$ git status
to double check that the only files I want to commit are staged, and then type$ git commit -m "added line to calculate sum".
After fileA, fileB, and fileC are committed, I can stage fileD and type$ git commit -m "removed lines that didn't work".
Staging helps Git understand which files you want to group together for a single commit. Files will remain unstaged until you stage them yourself. You can do this for each individual file by typing
$ git add [filename.extension]or stage all unstaged files by typing
$ git add *When you’re ready to commit, type
$ git commit -m "comment"The “-m” tells Git that the following sentence in quotations is your commit message. A good commit message explains what you did, why you did it, and can easily be understood by others viewing your script. Try to keep commit messages short—about 50 characters or less.
Now you know how to connect your repository to git, stage your files, and commit your changes! The steps outlined above highlight some of the common Git commands, but is by no means exhaustive. Git is a powerful tool that every coder should have, regardless if you’re a professional software engineer or someone like me, who uses it for research. Coding comes with a steep learning curve, but once you get the hang of it, it can be one of the most fun parts of your job! Keep an eye out for a future post on how to collaborate with others using an extension of Git—GitHub.
Remember those basic concepts you learned for the grade-school science fair? Well, I’m going to let you in on a little secret: many of them are used in university-level research. For example, I remember hearing about students replicating their previous year’s projects in middle school and high school. At the time, it felt pointless. What more could you learn from repeating something you’ve already done before?
This was definitely due to my childhood bias against science fair. Every year it felt like I was just making up a project and not actually learning anything. Science fair was mandatory until 9th grade, so high schoolers choosing to build on existing projects seemed like a monumental waste of time. Thankfully, pursuing science in college changed my perspective.
College-level science classes are chock full of research articles, all of which follow a standardized format. For instance, authors use the introduction section to cite background research and explain the purpose of their study. Over time, I recognized researchers citing their own previous publications in the introduction. It’s like adult version of replicating a science fair project, but this time I could read an explanation about why the replication was necessary. Uncovering a new scientific concept is exciting, but its significance may dissipate if others can’t get similar results. Whether it’s science fair or academic research, repetition is necessary to cement the validity and importance of an experiment’s outcome.
270 psychologists in the early 2010s replicated 100 studies from 2008, drawing inspiration from replication attempts in cell biology.1 The biology replications faced issues, including insufficient details about the procedure and results, leading to successful replications less than 25% of the time. The psychologists tried circumventing this, often by collaborating with the original papers’ authors, but they maintained that “a large portion of replications produced weaker evidence for the original findings.”
Despite having the necessary background knowledge, combing through the original publications, contacting the respective researchers, and replicating each experiment to the best of their ability, they still wound up with largely inconclusive results.
This was from only one year of psychology publications.
Low replication rates aren’t restricted to the natural sciences, either. In 2015, the US Federal Reserve Board examined 59 publications from 13 influential economics journals.2 Again, despite assistance from the original authors, only 29 studies (49%) had successful replications. Seeing differences between a study’s original results and a replication’s results is possible, but poor replication rates, year over year, across disciplines suggests a deeper, systemic problem. This issue, referred to as the replication crisis, likely stems from the widespread use of questionable research practices (QRPs).
Let’s say I went to a nearby park and asked about 100 people if they prefer lemonade or iced tea. I hypothesized lemonade would be the more popular choice since everyone I know prefers lemonade.
The first 10 people were split down the middle, with 5 picking lemonade and 5 choosing iced tea. Definitely not what I was expecting. A few minutes later, 10 soccer players from a nearby game ran up and all chose lemonade. Now, out of 20 people total, only 5 picked iced tea! Satisfied with the results of my small sample, I packed up my things and headed home.
This is an example of two QRPs: confirmation bias and optional stopping. I used the soccer players’ choices as confirmation that my hypothesis (based on my bias towards lemonade) was correct even though the first 10 people were split half and half. Stopping my experiment before reaching 100 people lead to a false positive conclusion, so replication with a new sample of 20 people may yield different results.
I told my friend Jess about my experiment, and she had some issues with my methods. Her family’s annual reunion was around the corner, and they anticipated about 100 people in attendance; the perfect opportunity for Jess to replicate my study with the appropriate sample size.
Caught up in organizing the reunion, she decided not to waste time coming up with a hypothesis. Handing out drinks and logging the data on her phone would be good enough, right? After everyone went home, she looked at her results and noticed that about 70 people chose iced tea and 30 people chose lemonade.
Jess marched over to my house the next day claiming her larger sample size supported her hypothesis about people preferring iced tea. Annoyed by how smug she looked, I probed her for more information and learned that she also engaged in a QRP: hypothesizing after her results were known (HARKing). Jess asserted that her results supported her hypothesis even though she didn’t have one before collecting data.
Implementation of HARKing, optional stopping, and other QRPs resulted in many published papers with positive, statistically significant results having little to no significance when replicated. Conducting research with as much transparency as possible not only reduces the chance of a researcher using QRPs, but also makes it immensely easier to replicate studies. Luckily, open science addresses this exact issue.
At its core, the open science movement strives to “increase openness, integrity, and reproducibility” in published research.4 One of the first steps in the open science process is preregistration: researchers use an online platform to log their hypotheses, study protocol, and anticipated statistical analyses before collecting data. All preregistered information has the date and time of submission and is accessible to peer-reviewers as well as other professionals in the field. Additionally, researchers can upload a preprint of their article—an accessible, near-final version of their paper before it’s peer-reviewed for publication.
Widespread use of open science methods at the time of the psychology, biology, and economics replication studies may have led to a higher likelihood of obtaining results similar to the original papers. All that accessible information clarifies the experimental process for everyone involved and ensures that studies are conducted as honestly as possible.
All that said, just because a replication (or replications) led to different results doesn’t always mean that the initial conclusions were incorrect; science is imperfect, and differences in results could stem from a multitude of variables. At the end of the day, it’s important to remember that the goal of research isn’t to be right, it’s to uncover the truth behind things we can’t yet explain. Unexpected results may spur new research questions and lead to advancements of equal or greater importance. Addressing the replication crisis with open science is still relatively new but it’s a fantastic start to maintaining scientific integrity in the modern era.
Between our new research assistants, newly funded studies, and a new postdoc, the AWL has had a busy semester! Check out the video below for some of the highlights:
If you couldn’t already tell, the Aging Well Lab team are big fans of neuroscience. More specifically, the neuroscience of aging and decision making. Neuro can be a pretty daunting subject, though, especially for newcomers. Overall, developments in advanced sciences are relatively inaccessible; peer-reviewed journal articles sit behind paywalls and are riddled with jargon. News reports relaying said findings can be equally as convoluted, or even worse, the message gets misinterpreted in an attempt to “dumb it down” for the average consumer.
The way we in the AWL see it, anyone in pursuit of knowledge deserves an honest chance at understanding the material, regardless of their academic background; we strive to promote these ideals in neuroscience, decision making, aging, and academic research as a whole. The purpose of this blog is to disseminate the latest research, from our lab and others engaged in this work, in a fun and understandable way to anyone who is interested. We can’t wait to share our love for science with you all!